


中國人工智能初創公司深度求索(DeepSeek)3月24日深夜低調上線了DeepSeek-V3的新版本DeepSeek-V3-0324,參數量為6850億,在代碼、數學、推理等多個方面的能力再次顯著提升,甚至代碼能力追平美國Anthropic公司大模型Claude 3.7。
不過,外界對于DeepSeek-V3-0324的關注并不僅僅因為該版本的能力提升,而是猜測它的發布是否意味著DeepSeek更新一代的V4與R2大模型的發布不遠了。
在回答《環球時報》記者有關DeepSeek-V3新版本有哪些能力提升時,DeepSeek表示,一是新版本代碼能力顯著提升,接近Claude 3.7水平。例如,有用戶在實測中發現,V3-0324能一次性生成800行無錯誤的網頁代碼,并實現動態響應式布局和交互效果。二是數學與邏輯推理能力增強。例如經典的“4升水壺問題”和數學競賽題(如AIME 2025題目),部分表現接近專業推理模型。三是模型架構與開源生態。V3-0324采用MIT許可證,允許自由修改、分發及商業化應用,進一步降低了開發者的使用門檻。
清華大學新聞學院、人工智能學院教授沈陽25日對《環球時報》記者表示,DeepSeek-V3-0324不僅是V3系列的一次迭代,更是中國AI技術崛起的又一力證。其在性能、效率和開源策略上的綜合優勢使其在全球大語言模型領域占據重要地位。未來,DeepSeek可能通過推理能力提升和多模態擴展來鞏固技術領先優勢,同時在中美競爭和社區生態中尋找平衡。沈陽認為,DeepSeek-V3-0324的發布看似是一次“小更新”,但其性能跳躍表明該團隊可能在為后續重大版本(如傳言中的DeepSeek-R2或V4)鋪路。
路透社今年2月底引述3名知情人士的說法宣稱,DeepSeek原計劃在今年5月初發布R2,但現在希望盡早推出,具體時間尚未透露。此外,DeepSeek希望新模型在代碼生成和多語言推理方面的表現進一步提升。不過,外媒的相關傳言并沒有得到DeepSeek公司的證實與回應。
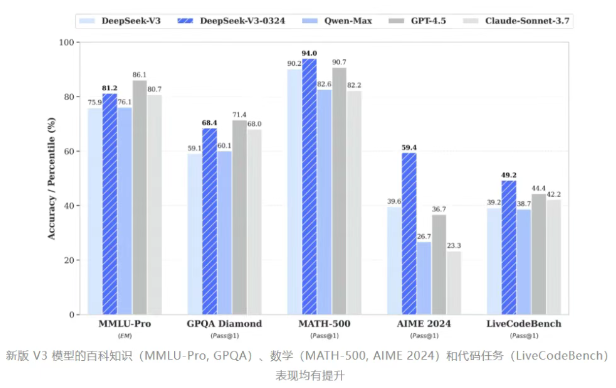
沈陽表示,DeepSeek-V3-0324的推出進一步凸顯中國AI企業在技術與成本上的競爭力。美國對華GPU出口限制可能促使中國企業加速國產硬件適配,同時其開源模式或引發西方廠商的連鎖動作,例如推出更強閉源模型。2025年可能是中美AI競爭的分水嶺。
沈陽認為,在OpenAI公司的GPT大模型要把通用大模型和推理大模型融合在一起的背景下,外界關注包括DeepSeek在內的中國頭部大模型是不是最終也會出現這種合并的趨勢。“這種可能是存在的,因為對于用戶來說,并不關心大模型在回應自身問題時用的是什么類型的模型,更關心大模型能不能給出更為智能、合理的參考答案。”(據環球時報)

請輸入驗證碼